
 sign in
sign in
 join
join
Computer Vision API 버전 1.0
- 본 번역문서의 원문은 Computer Vision API Version 1.0 docs.microsoft.com 입니다.
- 본 번역문서는 인공지능 : Computer Vision API 버전 1.0 www.taeyo.net 에서도 함께 제공됩니다.
클라우드 기반의 Computer Vision API를 사용하면 이미지를 처리하거나 이미지의 정보를 반환하는 고급 알고리즘을 사용할 수 있습니다. Microsoft Computer Vision 알고리즘은 이미지를 업로드하거나 이미지의 URL을 지정해서, 입력 및 사용자의 선택에 따라 다양한 방식으로 시각적 콘텐츠를 분석할 수 있습니다. Computer Vision API 사용자는 이미지 분석을 이용해서 다음과 같은 작업을 수행할 수 있습니다:
- 이미지 내용을 바탕으로 이미지에 태그 달기
- 이미지 분류하기
- 이미지 유형 및 품질 확인하기
- 이미지에 포함된 사람의 얼굴을 감지하고 좌표 반환받기
- 특정 도메인에 대한 내용 인식하기
- 이미지 내용에 대한 설명 생성하기
- 이미지의 색 구성표 식별하기
- 성인 콘텐츠 제한하기
- 광학 문자 인식을 이용해서 이미지에 포함된 인쇄된 텍스트 식별하기
- 필기체 텍스트 인식하기
- 썸네일로 사용할 사진 자르기
요구 사항
- 지원되는 입력 방식: application/octet-stream 형식의 원시 이미지 이진 콘텐츠 또는 이미지 URL
- 지원되는 이미지 형식: JPEG, PNG, GIF, BMP
- 이미지 파일 크기: 4 MB 미만
- 이미지 크기: 50 x 50 픽셀 이상
이미지에 태그 달기
Computer Vision API는 2000 가지 이상의 인식 가능한 개체, 생명체, 풍경 및 동작에 기반한 태그를 반환합니다. 태그가 모호하거나 일반적이지 않은 경우, 태그의 의미를 명확하게 해주는 알려진 설정 상황에 따른 '힌트'가 API의 응답에 포합됩니다. 태그는 특정 방식으로 분류되어 구성되지 않으며, 상속 계층 구조도 존재하지 않습니다. 콘텐츠 태그 모음은 사람이 읽을 수 있는 완전한 문장으로 표시되는 이미지 '설명'의 토대가 됩니다. 다만, 현재 이미지 설명을 지원하는 유일한 언어는 영어뿐입니다.
이미지를 업로드하거나 이미지 URL을 지정하면, Computer Vision API 알고리즘이 이미지로부터 식별된 개체, 생명체 및 동작을 기반으로 태그를 출력합니다. 이 태그는 전면에 위치한 사람 같은 주요 대상에만 국한되지 않고, 설정 상황(실내 또는 실외), 가구, 도구, 식물, 동물, 장식품, 부속품 등까지 포함되어 반환됩니다.
예제

반환된 Json
{
'tags':[
{
"name":"grass",
"confidence":0.999999761581421
},
{
"name":"outdoor",
"confidence":0.999970674514771
},
{
"name":"sky",
"confidence":0.999289751052856
},
{
"name":"building",
"confidence":0.996463239192963
},
{
"name":"house",
"confidence":0.992798030376434
},
{
"name":"lawn",
"confidence":0.822680294513702
},
{
"name":"green",
"confidence":0.641222536563873
},
{
"name":"residential",
"confidence":0.314032256603241
},
],
}
이미지 분류하기
Computer Vision API는 태그나 설명 외에도, 기존 버전에서 정의된 분류에 기반한 범주를 반환합니다. 이 범주는 부모/자식 간의 상속 계층이 존재하는 분류 체계로 구성되어 있습니다. 모든 분류는 영어로 정의되어 있으며, 단독으로 또는 새로운 모델과 함께 사용할 수 있습니다.
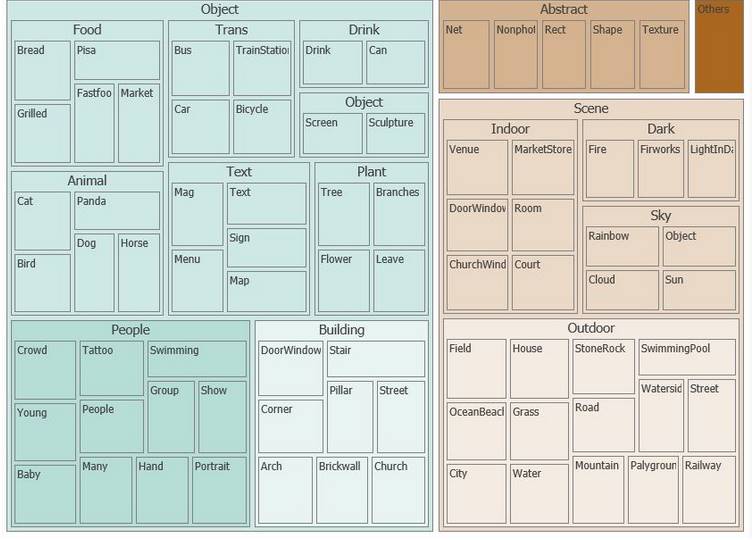
86 가지 범주 개념
다음 다이어그램에서 볼 수 있는 86 가지 개념 목록에 기반해서 이미지에서 발견되는 시각적 특징을 포괄적 범주로부터 구체적인 범주에 이르기까지 분류 가능합니다. 텍스트 형식의 전체 분류 목록은 Category Taxonomy 문서에서 확인하실 수 있습니다.
| 이미지 | 응답 |
|---|---|
 |
people |
 |
people_crowd |
 |
animal_dog |
 |
outdoor_mountain |
 |
food_bread |
이미지 유형 확인하기
이미지를 분류하는 방식은 다양합니다. Computer Vision API는 이미지가 흑백인지 아니면 컬러인지 여부를 뜻하는 불리언 (Boolean) 플래그를 설정할 수 있습니다. 또한 선 그리기 (Line Drawing) 이미지 여부를 뜻하는 플래그도 설정 가능합니다. 0-3의 점수로 클립아트 이미지 여부 및 이미지의 품질을 나타낼 수도 있습니다.
클립아트 형식
이미지가 클립아트인지 여부를 감지합니다.
| 값 | 의미 |
|---|---|
| 0 | Non-clip-art |
| 1 | ambiguous |
| 2 | normal-clip-art |
| 3 | good-clip-art |
| 이미지 | 응답 |
|---|---|
 |
3 good-clip-art |
|
0 Non-clip-art |
선 그리기 형식
이미지가 선 그리기 이미지인지 여부를 감지합니다.
| 이미지 | 응답 |
|---|---|
 |
True |
 |
False |
얼굴
사진에 포함된 사람의 얼굴을 감지해서 얼굴의 좌표, 얼굴을 담고 있는 사각형 좌표, 성별 및 나이를 반환합니다. 이 시각적 특징들은 얼굴에 관해서 생성된 메타데이터의 하위 집합입니다. 얼굴에 대한 보다 광범위한 메타데이터가 필요하다면 (안면 인식, 자세 감지 등) Face API를 사용하십시오.
| 이미지 | 응답 |
|---|---|
 |
[ { "age": 23, "gender": "Female", "faceRectangle": { "left": 1379, "top": 320, "width": 310, "height": 310 } } ] |
 |
[ { "age": 28, "gender": "Female", "faceRectangle": { "left": 447, "top": 195, "width": 162, "height": 162 } }, { "age": 10, "gender": "Male", "faceRectangle": { "left": 355, "top": 87, "width": 143, "height": 143 } } ] |
 |
[ { "age": 11, "gender": "Male", "faceRectangle": { "left": 113, "top": 314, "width": 222, "height": 222 } }, { "age": 11, "gender": "Female", "faceRectangle": { "left": 1200, "top": 632, "width": 215, "height": 215 } }, { "age": 41, "gender": "Male", "faceRectangle": { "left": 514, "top": 223, "width": 205, "height": 205 } }, { "age": 37, "gender": "Female", "faceRectangle": { "left": 1008, "top": 277, "width": 201, "height": 201 } } ] |
특정 도메인에 대한 내용 인식하기
Computer Vision API는 태깅 기능이나 최상위 수준의 분류 기능 외에도, 전문 정보 (또는 특정 도메인에 관한 정보) 관련 기능을 지원합니다. 전문 정보는 별도 메서드로 구현되거나 최상위 수준의 분류 기능을 더하여 구현 가능합니다. 이 기능은 도메인 특정 (Domain-Specific) 모델을 추가함으로써 86 가지 범주 분류를 더 세부적으로 정의할 수 있는 수단으로 사용됩니다.
다만, 현재 지원되는 전문 정보는 유명인사 인식과 랜드마크 인식이 전부로, 인물 및 인물 그룹 범주와 전 세계의 랜드마크에 대한 도메인 특정 상세 검색 기능을 제공합니다.
도메인 특정 모델을 사용할 수 있는 방법은 두 가지입니다:
첫 번째 옵션 - 범위 분석
HTTP POST 호출을 수행해서 선택한 모델만 분석하는 방법입니다. 이 경우, 사용하고자 하는 모델을 알고 있으면 모델의 이름을 지정해서 해당 모델과 관련된 정보만 가져올 수 있습니다. 가령, 이 방식을 사용해서 유명인사 인식만 검색할 수 있습니다. 그러면 응답으로 유명인사일 가능성이 높은 사람들의 목록이 신뢰도 점수와 함께 포함되어 반환됩니다.
두 번째 옵션 - 고급 분석
분석을 통해서 86 가지 범주 분류와 관련된 추가적인 세부 정보를 제공합니다. 이 방식은 한 가지 이상의 도메인 특정 모델의 세부 사항과 일반적인 이미지 분석 결과를 동시에 얻고자 하는 응용 프로그램에서 사용할 수 있습니다. 이 메서드가 호출되면 먼저 86 가지 범주 분류 분류자(Classifier)가 호출됩니다. 그리고 알려진/일치하는 모델과 일치하는 범주가 존재할 경우, 뒤이어 분류자 호출의 두 번째 과정이 수행됩니다. 가령, 'details=all'이거나 'details'에 'celebrities'가 포함된 경우, 이 메서드는 86 가지 범주에 대한 분류자가 호출된 뒤에 유명인사 분류자를 호출합니다. 그에 따라 결과에 'people_'로 시작하는 태그가 포함됩니다.
설명 생성하기
Computer Vision API의 알고리즘은 이미지의 내용을 분석하며, 이는 사람이 읽을 수 있는 완전한 문장의 언어로 표시되는 '설명'의 토대가 됩니다. 이 설명은 이미지에서 발견된 내용을 요약합니다. Computer Vision API의 알고리즘은 이미지에서 식별된 개체를 바탕으로 다양한 설명을 만들어냅니다. 각각의 설명은 평가되고 신뢰 점수가 매겨집니다. 그런 다음, 가장 높은 신뢰 점수부터 가장 낮은 점수의 순서로 정렬된 목록이 반환됩니다. 여기에서 이 기술을 이용해서 이미지 캡션을 생성하는 봇의 예제를 살펴볼 수 있습니다.
설명 생성 예제

반환된 Json
'description':{
"captions":[
{
"type":"phrase",
'text':'a black and white photo of a large city',
'confidence':0.607638706850331
}
]
"captions":[
{
"type":"phrase",
'text':'a photo of a large city',
'confidence':0.577256764264197
}
]
"captions":[
{
"type":"phrase",
'text':'a black and white photo of a city',
'confidence':0.538493271791207
}
]
'description':[
"tags":{
"outdoor",
"city",
"building",
"photo",
"large",
}
]
}
색 구성표 식별하기
Computer Vision 알고리즘은 이미지로부터 색상을 추출할 수 있습니다. 색상은 전경, 배경 및 전체의 세 가지 관점으로 분석되어, 12 가지 강조색으로 분류됩니다. 강조색은 검정(Black), 파랑(Blue), 갈색(Brown), 회색(Gray), 녹색(Green), 주황색(Orange), 분홍색(Pink), 자주색(Purple), 빨간색(Red), 청록색(Teal), 흰색(White) 및 노란색(Yellow)입니다. 이미지의 색상에 따라 간단한 흑백 또는 강조색이 16 진수 색상 코드로 반환됩니다.
| 이미지 | 전경색 | 배경색 | 색상 |
|---|---|---|---|
|
Black | Black | White |
|
Black | White | White, Black, Green |
 |
Black | Black | Black |
강조색
지배적 색상 및 채도의 혼합으로 사용자에게 가장 눈에 띄는 색상을 나타내는, 이미지로부터 추출한 색상입니다.
| 이미지 | 응답 |
|---|---|
|
#BC6F0F |
|
#CAA501 |
|
#484B83 |
흑백
이미지가 흑백인지 여부를 나타내는 불리언 플래그입니다.
| 이미지 | 응답 |
|---|---|
|
True |
|
False |
성인 콘텐츠 제한하기
다양한 시각적 범주 중에는 성인용 자료를 탐지하고 성적 내용이 포함된 이미지의 표시를 제한하는 성인 및 외설 그룹이 있습니다. 성인용 콘텐츠 및 외설적인 콘텐츠 감지용 필터는 사용자의 선호도에 따라 차등적으로 설정할 수 있습니다.
광학 문자 인식 (OCR, Optical Character Recognition)
OCR 기술은 이미지에 포함된 텍스트 내용을 감지해서 식별된 텍스트를 기계가 읽을 수 있는 문자 스트림으로 추출합니다. 그 결과를 검색 결과나 의료 기록, 보안 및 뱅킹 같은 다양한 목적으로 활용할 수 있습니다. OCR은 자동으로 언어를 감지합니다. OCR을 이용하면 텍스트를 일일이 기록하는 대신 텍스트의 사진만 찍어도 되므로 시간을 절약할 수 있고 또 편리합니다.
OCR은 25 가지 언어를 지원하는데 그 목록은 다음과 같습니다: 아랍어, 중국어 간체, 중국어 번체, 체코어, 덴마크어, 네덜란드어, 영어, 핀란드어, 프랑스어, 독일어, 그리스어, 헝가리어, 이탈리아어, 일본어, 한국어, 노르웨이어, 폴란드어, 포르투갈어, 루마니아어, 러시아어, 세르비아어 (키릴어 및 라틴어), 슬로바키아어, 스페인어, 스웨덴어 및 터키어.
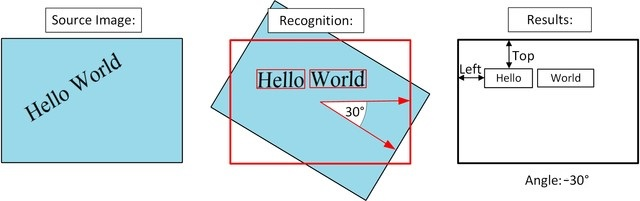
필요에 따라, OCR은 이미지의 수평 축을 기준으로 인식한 텍스트의 회전 각도를 수정합니다. 다음 그림과 같이 OCR은 각 단어의 프레임 좌표도 제공합니다.
OCR을 사용하기 위해서는:
- 입력 이미지의 크기가 40 x 40 픽셀에서 3200 x 3200 픽셀 사이여야 합니다.
- 이미지의 크기는 10 메가 픽셀보다 클 수 없습니다.
입력 이미지는 90 도의 배수에서 추가로 최대 40 도까지 회전할 수 있습니다.
텍스트의 인식 정확도는 이미지의 품질에 따라서 달라집니다. 다음과 같은 경우 인식이 부정확할 수 있습니다:
- 흐릿한 이미지
- 필기 또는 필기체 텍스트
- 예술적 글꼴 스타일
- 작은 텍스트 크기
- 복잡한 배경, 그림자 또는 환한 빛이 텍스트를 가리고 있거나 원근이 왜곡된 경우
- 단어의 시작 부분에 대문자가 너무 크거나 누락되어 있는 경우
- 아래 첨자, 위 첨자 또는 취소선 텍스트
제한 사항: 텍스트가 지배적인 사진에서는 부분 인식되는 단어로 인해 가양성(False Positives)이 발생할 수 있습니다. 일부 사진, 특히 텍스트가 존재하지 않는 사진의 경우, 이미지 형식에 따라서 정밀도가 크게 달라질 수 있습니다.
필기체 텍스트 인식하기
이 기술을 사용하면 메모, 편지, 에세이, 화이트보드, 양식 등에서 손으로 쓴 텍스트를 감지하고 추출할 수 있습니다. 이 기술은 백지, 노란색 스티커 메모 및 화이트보드 같은 다양한 표면 및 배경에서 동작합니다.
필기체 텍스트 인식은 시간과 노력을 절약해주며, 텍스트를 필사하는 대신 사진으로 찍을 수 있으므로 생산성을 높일 수 있습니다. 노트를 디지털화 시킬 수 있으며, 이를 통해서 빠르고 쉬운 검색을 구현할 수 있습니다. 결과적으로 낭비되는 종이를 줄일 수 있습니다.
입력 요구 사항은 다음과 같습니다:
- 지원되는 이미지 형식: JPEG, PNG 및 BMP.
- 이미지 파일의 크기는 4 MB 보다 작아야 합니다.
- 이미지의 크기는 최소 40 x 40 픽셀보다 크고, 최대 3200 x 3200 픽셀보다 작아야 합니다.
노트: 이 기술은 현재 미리보기 상태로 제공되며 영어 텍스트에만 사용 가능합니다.
썸네일 생성하기
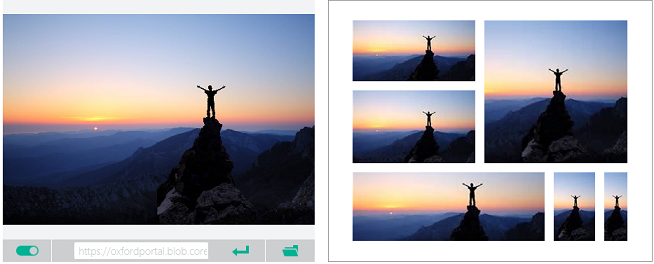
썸네일은 전체 크기의 이미지를 작게 표현한 것입니다. 전화기, 태블릿, 그리고 PC 같은 다양한 장치들은 서로 다른 사용자 경험(UX) 레이아웃과 썸네일 크기가 필요합니다. Computer Vision API의 스마트 자르기 기능을 이용하면 이 문제를 해결하는 데 도움이 됩니다.
이미지를 업로드하면, 고품질의 썸네일이 생성되고 Computer Vision API 알고리즘이 이미지에 포함된 개체를 분석합니다. 그런 다음, '관심 영역(ROI, Region of Interest)'의 요구 사항에 맞춰 이미지를 자릅니다. 출력은 다음 그림과 같이 특별한 틀 내에 표시됩니다. 생성된 썸네일은 사용자의 요구에 따라서 원본 이미지의 종횡비와 다른 종횡비로 표현될 수 있습니다.
썸네일 알고리즘은 다음과 같이 작동합니다.
- 이미지에서 산만한 요소들을 제외하고 주요 대상인 '관심 영역 (ROI)'을 인식합니다.
- 식별된 관심 영역을 기준으로 이미지를 자릅니다.
- 대상 썸네일 크기에 맞게 가로 세로 비율을 변경합니다.
- Computer Vision API 버전 1.0 2017-10-26 08:00
- Computer Vision API 구독 키 발급받기 2017-10-31 08:00
- Computer Vision API 호출하기 2017-11-02 08:00
- Computer Vision cURL 퀵 스타트 2017-11-07 08:00
- Computer Vision C# 퀵 스타트 2017-11-09 08:00
- Computer Vision Java 퀵 스타트 2017-11-14 08:00
- Computer Vision JavaScript 퀵 스타트 2017-11-16 08:00
- Computer Vision API C# 자습서 2017-11-21 08:00
- Computer Vision API Java 자습서 2017-11-23 08:00
- Computer Vision API JavaScript 자습서 2017-11-28 08:00
- 실시간 동영상 분석하기 2017-11-30 08:00



