
 sign in
sign in
 join
join
Windows에서 .NET C#으로 Speech Recognition API 시작하기
본문에서는 Speech Recognition API를 사용해서 음성 오디오를 텍스트로 변환하는 기초적인 Windows 응용 프로그램의 개발 방법을 살펴봅니다. 클라이언트 라이브러리를 이용하면 실시간 스트리밍이 가능하기 때문에, 클라이언트 응용 프로그램에서 오디오를 서비스에 전송함과 동시에 비동기적으로 부분적 인식 결과를 수신할 수 있습니다.
모든 장치에서 실행되는 응용 프로그램에서 Speech Service를 사용하려는 개발자는 C# 데스크톱 라이브러리를 사용하면 됩니다. 라이브러리를 사용하려면 32 비트 플랫폼 용 Microsoft.ProjectOxford.SpeechRecognition-x86 NuGet 패키지나 64 비트 플랫폼 용 Microsoft.ProjectOxford.SpeechRecognition-x64 NuGet 패키지를 설치해야 합니다. 클라이언트 라이브러리 API 참조는 Microsoft Speech C# desktop library 페이지를 참고하시기 바랍니다.
이어지는 절에서는 C# 데스크톱 라이브러리를 이용해서 C# 예제 응용 프로그램을 설치하고, 빌드하고, 실행하는 방법을 살펴봅니다.
요구 사항
플랫폼 요구 사항
다음 예제는 Visual Studio 2015, Community Edition을 사용해서 Windows 8 이상 및 .NET Framework 4.5 이상을 대상으로 개발되었습니다.
예제 응용 프로그램 가져오기
Speech C# desktop library sample 저장소에서 예제를 복제합니다.
Speech Recognition API 구독 및 무료 평가판 구독 키 발급받기
Speech API는 Microsoft Cognitive Services의 (구 프로젝트 Oxford) 일부분입니다. 무료 평가판 구독 키는 Cognitive Services 체험하기 페이지에서 발급받을 수 있습니다. 음성 탭에서 Bing Speech API를 선택한 다음, API 키 가져오기(Get API Key) 버튼을 클릭합니다. 그러면 기본 키와 보조 키가 발급됩니다. 두 키 모두 동일한 할당량에 연결되어 있으므로 두 키 중 아무 키나 사용해도 무방합니다.
중요
-
구독 키 발급받기. Speech 클라이언트 라이브러리를 사용하려면 반드시 구독 키가 필요합니다.
-
구독 키 사용하기. 제공되는 C# 데스크톱 예제 응용 프로그램을 실행할 때 텍스트 상자에 발급받은 구독 키를 붙여 넣습니다. 보다 자세한 정보는 예제 응용 프로그램 실행하기 절을 참고하시기 바랍니다.
단계 1: 예제 응용 프로그램 설치하기
-
Visual Studio 2015를 실행하고 파일(File) > 열기(Open) > 프로젝트/솔루션(Project/Solution)을 선택합니다.
-
다운로드 받은 Speech Recognition API 파일들이 저장된 폴더로 이동합니다. Speech > Windows를 선택한 다음, Sample-WP 폴더를 선택합니다.
-
SpeechToText-WPF-Samples.sln이라는 이름의 Visual Studio 2015 솔루션 (.sln) 파일을 더블 클릭합니다. 그러면 Visual Studio에 솔루션이 열립니다.
역주
2018년 1월 현재, 폴더 구조가 변경됐으며, 그냥 저장소 루트 폴더에 위치한 SpeechToText-WPF-Sample.sln 파일을 더블 클릭하면 됩니다. 그리고 SpeechToText-WPF-Sample-x64 프로젝트와 SpeechToText-WPF-Sample-x86 프로젝트 중, 자신의 환경에 맞는 프로젝트를 시작 프로젝트로 설정하면 됩니다.
단계 2: 예제 응용 프로그램 빌드하기
-
만약 인텐트를 이용한 인식 기능을 사용하고자 한다면, 먼저 LUIS(Language Understanding Intelligent Service)를 등록해야 합니다. 그리고 samples/SpeechRecognitionServiceExample 폴더에 위치한 app.config 파일을 열고,
LuisEndpointUrl키의 값을 사용하려는 LUIS 응용 프로그램의 끝점 URL로 설정합니다. LUIS 응용 프로그램의 끝점 URL에 관한 더 자세한 정보는 Publish your app 문서를 참고하시기 바랍니다.팁
LUIS 끝점 URL의
&문자를&로 변경해야 XML 파서가 URL을 올바르게 해석할 수 있습니다. -
Ctrl+Shift+B 키를 누르거나, 리본 메뉴에서 빌드(Build)를 선택한 다음, 솔루션 빌드(Build Solution)를 선택합니다.
단계 3: 예제 응용 프로그램 실행하기
-
빌드가 완료되면, F5 키를 누르거나 리본 메뉴에서 시작(Start)을 선택해서 예제 응용 프로그램을 실행합니다.
-
그러면 Project Cognitive Services Speech To Text Sample 창이 실행됩니다. 발급받은 구독 키를 지시에 따라 Paste your subscription key here to start 텍스트 상자에 붙여 넣습니다. PC나 노트북에 구독 키를 저장해 놓고 싶다면 Save Key 버튼을 클릭합니다. 반대로 시스템에서 구독 키를 삭제하고 싶다면 Delete Key 버튼을 클릭해서 PC나 노트북에서 구독 키를 제거합니다.

-
Speech Recognition Source 하위의 6 가지 음성 원본 중 하나를 선택합니다. 이 소스들은 두 가지 주요 입력 범주를 갖고 있습니다:
- 음성을 캡처하려면 컴퓨터의 마이크나 추가로 설치된 마이크를 사용합니다.
- 오디오 파일을 재생합니다.
그리고 각 범주는 각각 세 가지 인식 모드를 갖고 있습니다:
-
ShortPhrase 모드: 최대 15 초까지 말하거나 데이터를 전달할 수 있습니다. 데이터가 서버로 전송되면, 클라이언트는 여러 번의 부분 결과와 n-BEST 선택 항목 형태의 단일 최종 결과를 반환받습니다.
-
LongDictation 모드: 최대 2 분까지 말하거나 데이터를 전달할 수 있습니다. 데이터가 서버로 전송되면, 클라이언트는 서버가 감지한 문장의 일시 중지 위치에 따라 여러 번의 부분 결과와 여러 번의 최종 결과를 반환받습니다.
-
인텐드 감지: 서버가 음성 입력에 관한 구조화된 정보를 추가적으로 반환합니다. 인텐드 감지를 사용하려면 먼저 LUIS를 이용해서 모델을 훈련시켜야 합니다.
예제 응용 프로그램에는 예제 오디오 파일들이 함께 포함되어 있습니다. 이 파일들은 본문의 예제와 함께 다운로드 받은 저장소의 samples/SpeechRecognitionServiceExample 폴더 하위에 위치해 있습니다. 음성 입력으로 Use wav file for Shortphrase mode나 Use wav file for Longdictation mode를 선택하고 다른 파일을 선택하지 않으면 이 예제 오디오 파일들이 자동으로 실행됩니다. 현재는 WAV 오디오 포멧만 지원됩니다.
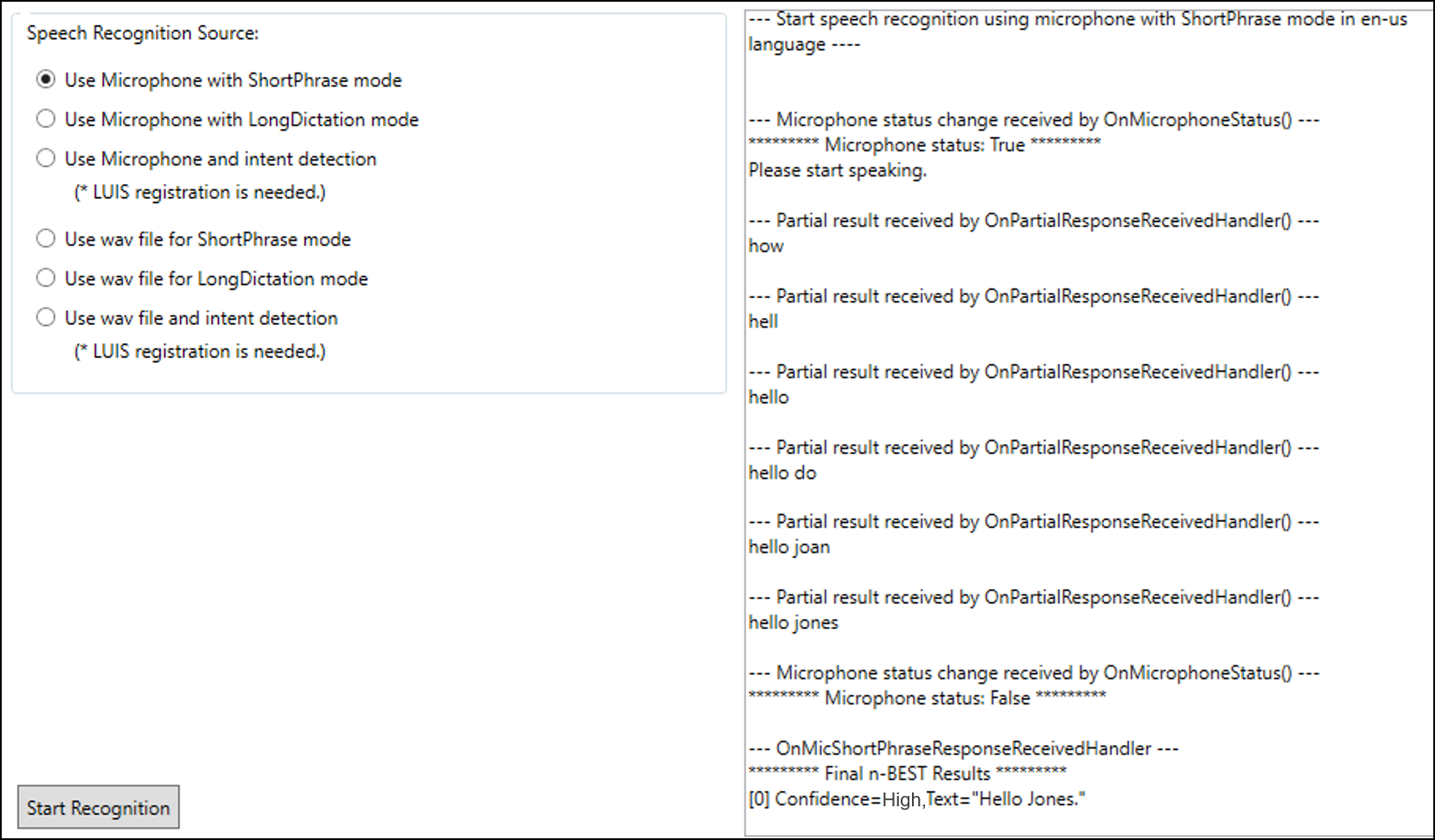
예제 살펴보기
인식 이벤트
-
Partial Results 이벤트: 말하기를 멈추거나 (
MicrophoneRecognitionClient를 사용할 경우) 데이터 전송을 마치지 않았어도 (DataRecognitionClient를 사용할 경우), 여러분이 말하는 내용을 Speech Service가 예측할 때마다 매번 호출됩니다. -
Error 이벤트: 서비스가 오류를 감지하면 호출됩니다.
-
Intent 이벤트: 최종 인식 결과가 구조화된 JSON 인텐트로 파싱된 후, "WithIntent" 클라이언트에서 (
ShortPhrase모드에서만) 호출됩니다. -
Result 이벤트:
-
ShortPhrase모드의 경우, 말하기를 멈추면 호출되어 n-BEST 결과를 반환합니다. -
LongDictation모드의 경우, 서비스가 문장의 일시 중단을 식별한 위치에 따라 여러 번 호출됩니다. -
각각의 n-BEST 선택 항목마다, 신뢰값과 몇 가지 다른 형태의 인식된 텍스트가 반환됩니다. 더 자세한 내용은 Output format을 참고하시기 바랍니다.
-
이벤트 처리기는 코드에 이미 주석으로 표시되어 있습니다.
관련 자료
- Microsoft Speech API 개요 2018-01-30 08:00
- REST API를 이용한 음성 인식 시작하기 (PowerShell, cUrl, C#) 2018-02-01 08:00
- Windows에서 .NET C#으로 Speech Recognition API 시작하기 2018-02-06 08:00
- Windows에서 .NET C#으로 음성 인식 서비스 라이브러리 시작하기 2018-02-08 08:00
- JavaScript로 Speech Recognition API 시작하기 2018-02-13 08:00
- Android에서 Java로 음성 인식 시작하기 2018-02-15 08:00




