
 sign in
sign in
 join
join
VBScript 5.6과 정규 표현식(Regular Expression)
본문의 목적은 VBScript 5.0 버전에서부터 지원되고 있는 정규 표현식(Regular Expression)을 소개하는데 있으며, 글 내용과 제시되는 모든 샘플 코드는 VBScript의 가장 최신 버전인 VBScript 5.6을 기준으로 하고 있다. 그러나, 정규 표현식 그 자체에 관한 깊이 있는 내용을 다루고 있거나 정규 표현식의 전체적인 특성에 관하여 조목조목 설명하고 있는 글은 아니며, 단지 VBScript에서 지원하는 정규 표현식의 일부 특성에 관해서만 언급하고 있다.
정규 표현식은 그 자체로 매우 방대한 양의 주제와 응용을 갖고 있으며, 그에 관해 필자 정도의 지식 수준으로는 이렇다 저렇다 할 게재가 아니다. 다만, 필자는 VBScript에서 제공하고는 있으나 일반적으로 널리 알려지지 않은 강력한 기능인 정규 표현식을 여러분들에게 소개하고자 하는 것이다.
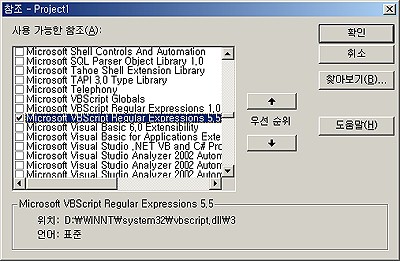
재미있는 사실은 VBScript는 5.0 버전에서부터 정규 표현식이 지원되고 있지만, 오히려 Microsoft Visual Basic 6.0에서는 SP 5가 배포된 현재까지도 정규 표현식이 지원되지 않고 있다는 점인데, 아마도 이는 Microsoft Visual Basic 6.0에서 VBScript에서 제공하는 정규 표현식 기능을 손쉽게 빌려쓸 수 있기 때문인 것으로 생각된다. Microsoft Visual Basic 6.0에서 VBScript의 정규 표현식 기능을 사용하려면, 다음 그림과 같이 Microsoft VBScript Regular Expressions X.X를 참조하면 된다.
사실 정규 표현식이라는 개념 자체는 VBScript에서 새로 만들어진 것이 아닌 상당히 오랜 역사를 지닌 개념으로, 전통적으로 다른 프로그래밍 언어에서는 벌써 오래 전부터 문자열 처리 부분에서 강력한 도구로 사용되어져 왔다. 그 가장 대표적인 예로는 Perl을 들 수 있으며 그 밖에도 마이크로소프트 계열의 프로그래머들에게는 조금 낯선 sed, awk, egrep, grep 등에서도 빈번히 사용되고 있다. 정규 표현식이 활용되고 있는 좀 더 친숙한 예는 바로 문서 편집기류의 응용 프로그램들인데, 일례로 현재 필자가 작업하고 있는 Homesite에서도 Find 기능과 Replace 기능에서 정규 표현식을 지원하고 있다.
필자는 정규 표현식을 조금이라도 사용해 보신 분이라면, 문자열 처리에는 정규 표현식 만한 것이 없다는 의견에 동의할 것이라고 믿는다.
VBScript에서는 RegExp라는 객체를 통해서 정규 표현식과 관련된 대부분의 기능을 제공하고 있는데, 이 객체는 다음 표와 같이 세 개의 메서드(Method)와 세 개의 프로퍼티(Property)를 갖고 있다.
메서드 목록
| Execute() | 정규 표현식 검색을 실행하고 패턴과 일치하는 문자열(들)의 집합을 리턴한다. |
|---|---|
| Replace() | 정규 표현식 패턴과 일치하는 문자열(들)을 지정한 문자열로 치환한다. |
| Test() | 정규 표현식 검색을 실행하고 일치되는 패턴이 있는지를 Boolean 형태로 리턴하다. |
프로퍼티 목록
| Global | 정규 표현식 검색시 전체 문자열을 검색할 것인지 여부를 결정한다. |
|---|---|
| IgnoreCase | 정규 표현식 검색시 대소문자를 구분할 것인지 여부를 결정한다. |
| Pattern | 검색할 정규 표현식 패턴을 설정하거나 반환한다. |
비록 RegExp 객체가 예상했던 것 보다는 상당히 간단한 구조를 가지고 있다는 것을 알 수 있지만, 이 표만 가지고서 정규 표현식의 전체적인 윤곽을 파악하기란 매우 어려울 일일 것이다. 이 여섯 개의 메서드와 프로퍼티들의 보다 상세한 내용은 샘플 코드와 함께 살펴보기로 하고, 그 전에 과연 정규 표현식을 사용할 경우 실제 프로그래밍에서 어떠한 이득을 얻을 수 있는 것인지 먼저 몇 가지 구체적인 예를 들어보기로 하겠다.
정규 표현식의 장점을 한 단어로 표현한다면 아마도 융통성 또는 유현함이 될 것이다. 지금부터 얘기하려는 사례는 필자가 실제로 경험한 것이기도 하고 정규 표현식이라는 개념을 처음 접하고 그 강력함에 놀라워했던 사례기도 하며, 정규 표현식의 대명사인 Perl을 무척이나 부러워하게끔 했었던 사례이기도 하다.
문자열을 다루는 작업 중에서 표현 형식에 관련된 가장 귀찮은 작업 한 가지를 말해보라고 한다면, 필자는 주저하지 않고 날짜라고 대답하겠다. 날짜라는 단어 자체가 주는 의미의 명확함에도 불구하고 실제 작업에서는 다양한 유형의 표현 형식이 존재한다. 가령, '2001/01/31', '01/31/2001', '2001.1.7', '01년 12월 1일' 등의 다양한 표현 형식으로 표기가 가능하다. 물론, 이 밖에도 '-'를 사용한다던가 월 부분에 영어 표기를 사용한다던가 하는 수 많은 변형이 있을 수 있다.
만약, 기존에 작성된 수 백건에서 수 천건 분량의 텍스트 형식의 자료가 텍스트 파일 또는 데이타베이스 테이블의 형태로 존재하고 있고, 이 자료들의 내부에 위에서 예로 든 것과 같이 다양한 표현 형식으로 표기된 날짜 문자열들이 산재해있다면, 그리고 이런 날짜 문자열들의 표현 형식을 한 가지로만 통일해야 한다면 어떻게 하는 것이 가장 빠르고 쉬운 방법이겠는가? 물론, VBScript 내에서도 FormatDateTime()이라는 내부 함수을 지원해주므로 이를 활용하는 방안을 생각해 볼 수도 있지만 FormatDateTime() 함수는 매우 제한적인 형태의 응용만이 가능할 뿐이다. 결정적으로 이 함수의 작업 결과는 해당 프로그램이 실행되고 있는 서버의 제어판에서 지정된 국가별 설정에 종속된다는 치명적인 단점이 있다.
여기서 왜 날짜의 표현 형식을 통일해야 하는 지는 명확하다. 날자를 기준으로 정렬을 해야할 수도 있고, 일정 기간 동안 작성된 자료만 간추려내야할 수도 있다. 만약, 순수한 VBScript만 가지고서 이 작업을 해야한다면 여러분들은 어떻게 하겠는가? 그리고, 이런 날짜 문자열들이 작업 대상이 되는 문자열 안에 있을 수도 있고, 없을 수도 있다면? 반드시 한 번만 있을 수 있는 것이 아니라, 여러 번 포함되어 있을 수도 있고 더군다나 각기 다른 표현 형식으로 표기되어 있다면? 만약, 필자에게 직장 상사가 이러한 작업을 순수한 VBScript만을 사용하여 해결할 것을 요구한다면 아마도 포기해 버릴 것 같다.
일단, 다양한 표현 형식의 날짜 문자열을 검색해야 한다. 검색한 후에는 Split() 함수를 사용하거나 기타 다른 방법을 사용해서 해당 날자 문자열을 각각 년, 월, 일의 요소로 분리해야하며 그 요소들의 표현 형식 또한 수정해줘야 한다. 즉, 월은 항상 두 자리여야 한다던가 영문으로 표기된 월을 숫자로 수정한다던가 하는 작업을 두고 하는 말이다. 그 다음에는 그 요소들을 표준 형식으로 조합한 후 원래의 날짜 문자열과 치환해야하는데 애초의 날짜 문자열과 변형된 날짜 문자열의 길이가 틀릴 수도 있으므로 날짜 문자열의 인덱스(Index) 값을 기준으로 끊거나 이어붙이는 작업을 몇 번 반복해야 한다.
더군다나 이런 작업 과정은 작업 대상 문자열 당 몇 번이 될지도 모를 일이며, 이런 루틴을 성공적으로 작성해낸다고 하더라도 그 실행 속도를 명확히 보장 받을 수 있을지는 장담할 수 없을 것이다. 이런 점들을 미루어 볼 때, 파일 시스템이나 데이타베이스에서 자료들을 읽어오거나 변경한 후 다시 기록하는 과정은 고려하지 않는다고 하더라도 결코 만만한 작업은 아닐 것이다.
필자는 실무에서 이와 비슷한 경우를 경험한 적이 있었는데, 구체적으로 말하자면 웹 상에서 실시간으로 각종 뉴스를 검색한 다음, 그 결과를 통합하고 정리하여 날짜순으로 정렬하거나 사용자가 지정하는 기간 동안의 기사만을 취합하여 보여주는 작업이었다. 그런데 문제는 각각의 신문사마다 날짜의 표현 형식이 상이했던 것이다. 심지어 어떤 신문사의 경우, 당일 기사는 날짜없이 기사 입력 시간만 출력되고 지난 기사일 경우에만 날짜가 출력되는 경우도 있었으니 이 문제의 복잡함을 더 이상 설명하지 않아도 충분히 상상할 수 있을 것이다.
필자가 직접 이 문제를 해결한 것은 아니었지만 실제로 이 문제를 해결하는 부분을 직접 보고나서 무척 놀랐었다. 각각의 표현 형식마다 몇 개의 단어로 이루어진 문자열을 경우의 수 만큼 연결한, 불과 100자 ~ 200자 내외의 문자열 한 줄로 이와 같은 문제를 말끔히 해결하고 있었던 것이다. 물론, 그것이 바로 정규 표현식 이었다는 점은 굳이 말할 필요가 없을 것이다. 더욱 놀라운 것은 위에서도 얘기했지만, 이 솔루션은 이런 작업을 웹 상에서 실시간으로 처리하는 것이었음에도 불구하고 전용선의 속도가 보장되는 경우에는 전혀 속도의 저하를 느낄 수 없었다는 사실이다. 결국, 이 말은 정규 표현식을 처리하는 부분에서는 거의 속도의 저하를 느끼지 못할 정도의 부하만 걸렸다는 뜻이 된다.
정규 표현식이 유용한 또 다른 예는 ASP.NET의 RegularExpressionValidator 컨트롤에서와 같이 임의의 문자열 패턴을 검증해야 하는 경우이다. 그 대표적인 예로 사용자가 입력한 E-Mail 주소나 홈페이지의 URL이 유효한 문자열인지 검증할 때나, 전화 번호와 같은 기타 특정 문자열 패턴의 유효성을 검증할 때와 같은 경우를 들 수 있다. 만약, VBScript 또는 JavaScript를 사용해서 이 작업을 수행한다면 위의 날짜의 예에서 보다는 간단하겠지만 그래도 최소한 몇 단계는 거쳐야 한다.
예를 들어, E-Mail 주소를 검증하는 경우, 먼저 '@' 문자와 '.' 문자가 문자열에 포함되었는지를 확인한 후, '.' 문자가 포함되었다면 몇 개나 포함되었는지 등을 알아보고 추가적으로 불필요한 특수 기호가 포함되었는지 확인하는 등의 단계를 더 거쳐야 한다. 그나마 전화 번호를 검증하는 예와 같은 경우는 좀 간단한 편이겠지만 그 검증의 대상이 URL인 경우와 같은 상황에서는 사정이 좀 더 복잡해진다. 다시 말해서, 확인해야 할 사항이 좀 더 많은 편인데 즉 'http://'라는 문자열로 시작해야만 하며 영문자와 숫자, 그리고 몇 가지 특수 기호만으로 구성되어야 하고 공백 문자는 포함될 수 없다. 이런 경우, 정규 표현식을 사용하면 각각의 문자열이 이러한 조건을 만족하는지 여부를 단번에 확인할 수 있다.
또한, 임의의 텍스트에서 특정 패턴의 문자열을 찾고 그 갯수와 위치, 길이 등등을 파악해야 하는 경우라면, 어떤 방법을 사용하는 것이 최선의 방법이겠는가? 이 경우 역시 VBScript만을 사용하여 문제를 해결할 수도 있겠지만 InStr() 함수 및 InStrRev() 함수 등을 사용하여 루프를 돌면서 하나씩 처리해야만 하고 결정적으로 찾으려는 것이 특정 문자열이 아닌 특정 패턴의 문자열이므로 문자열을 찾을 때나 그 길이를 구할 때 각각 나름대로 또 한 번의 처리를 거쳐야 한다. 이런 경우에도 역시 정규 표현식을 사용하면 단번에 처리할 수 있다.
그렇다면 도대체 본문 내내 필자가 그렇게 훌륭하다고 강조하고 있는 '정규 표현식'이라는 것은 구체적으로 어떤 것을 말하고 있는 것일까? 결론부터 말하자면 '정규 표현식'이라는 단어는 다음과 같은 형태의 문자열들을 지칭하는 것이다.
(\w+):\/\/([^/:]+)(:\d*)?([^# ]*)
Windows(?=95|98|NT)
^Chapter|Section [1-9][0-9]{0,1}$
이 정규 표현식 문자열들은 Windows Script V5.6 온라인 설명서 상의 몇몇 예제에서 필자의 임의대로 선택해본 것이다. 이런 정규 표현식 문자열들을 정규 표현식 패턴이라고 하는데, 아마 정규 표현식 패턴을 처음 접해보시는 분들에게는 조금 복잡해 보이고 그다지 한 눈에 쏙 들어올 만한 형태는 아닐 것이라고 생각한다. 만약, 위와 같은 정규 표현식 패턴들이 낯설게 느겨진다면 SQL 문의 LIKE 연산자를 생각해보기 바란다. 다음은 Microsoft SQL Server 2000의 온라인 설명서에서 LIKE 연산자와 관련된 부분 중 임의의 한 부분을 발췌한 것이다.
SELECT au_lname, au_fname, phone
FROM authors
WHERE au_lname LIKE '[CK]ars[eo]n'
ORDER BY au_lname ASC, au_fname ASC
이 SQL 문에서 붉은색으로 강조된 부분이 바로 LIKE 연산자가 사용된 부분이다. 비록 그 형태는 조금 틀리지만, 정규 표현식 패턴과 매우 유사한 형식임을 알 수 있다. 위의 LIKE 연산자의 예와 그 위의 정규 표현식 패턴의 예에서 가장 마지막 3번째 정규 표현식 패턴의 형태를 비교해보면 그 유사성을 알 수 있을 것이다. 사실 LIKE 연산자에 사용되는 패턴들도 역시 조금 특수한 형태의 정규 표현식 패턴이라고 말할 수 있으며, 양자간의 차이점이라고는 정규 표현식 쪽이 더 강력하고 연산자의 종류가 더 많다는 것 뿐이다.
어떤 관점에서는 LIKE 연산자로 응용되는 정규 표현식의 형태는 VBScript에서 정규 표현식 기능을 제공해주는 RegExp 객체의 세 가지 메서드인 Execute(), Replace(), Test() 중, 바로 Test() 메서드와 동일한 형태의 것이라고 봐도 큰 무리는 없을 것이다.
필자의 경험상 정규 표현식을 익힐 때, 가장 어려움을 느끼는 부분이 바로 이런 정규 표현식 패턴을 상황에 알맞게 작성하는 일이다. 거의 어지간이 눈에 익은 특수 문자란 특수 문자는 죄다 섞여 나오고, 더군다나 Escape 문자가 '\'인지라 패턴이 조금만 복잡해지면 이건 거의 암호에 가깝다. 그에 비해 코딩 자체는 거의 대부분의 경우 일정한 유형을 따르기 때문에 상대적으로 매우 쉽게 느껴진다.
다음은 Windows Script V5.6 온라인 설명서에서 발췌한 정규 표현식 패턴을 구성할 때 사용되는 모든 메타 문자와 해당 메타 문자의 동작을 정리한 표이다. 본문의 문맥과 이질감이 느껴지는 부분은 필자가 약간 수정했으나 기본적으로는 원본의 내용과 100% 동일하다.
| 문자 | 설명 |
|---|---|
| \ | 그 다음 문자를 특수 문자, 리터럴, 역참조, 또는 8 진수 이스케이프로 표시한다. 예를 들어, 'n' 은 문자 "n" 을 찾고 '\n' 은 줄 바꿈 문자를 찾는다. '\\' 시퀀스는 "\" 를 찾고 '\(' 는 "(" 를 찾는다. |
| ^ | 입력 문자열의 시작 위치를 찾는다. Multiline 속성이 설정되어 있으면 ^ 는 '\n' 또는 '\r' 앞의 위치를 찾는다. |
| $ | 입력 문자열의 끝 위치를 찾는다. Multiline 속성이 설정되어 있으면 $ 는 '\n' 또는 '\r' 뒤의 위치를 찾는다. |
| * | 부분식의 선행 문자를 0 개 이상 찾는다. 예를 들어, 'zo*' 는 "z", "zoo" 등이다. * 는 {0,} 와 같다. |
| + | 부분식의 선행 문자를 한 개 이상 찾는다. 예를 들어, 'zo+' 는 "zo", "zoo" 등이지만 "z" 는 아니다. + 는 {1,} 와 같다. |
| ? | 부분식의 선행 문자를 0 개 또는 한 개 찾는다. 예를 들어, "do(es)?" 는 "do" 또는 "does" 의 "do" 를 찾는다. ? 는 {0,1} 과 같다. |
| {n} | n 은 음이 아닌 정수이다. 정확히 n 개 찾는다. 예를 들어, 'o{2}' 는 "Bob" 의 "o" 는 찾지 않지만 "food" 의 o 두 개는 찾는다. |
| {n,} | n 은 음이 아닌 정수이다. 정확히 n 개 찾는다. 예를 들어, 'o{2}' 는 "Bob" 의 "o" 는 찾지 않지만 "foooood" 의 모든 o 는 찾는다. 'o{1,}' 는 'o+' 와 같고, 'o{0,}' 는 'o*' 와 같다. |
| {n,m} | m 과 n 은 음이 아닌 정수이다. 여기서 m 은 n 보다 크거나 같다. 최소 n 개, 최대 m 개 찾는다. 예를 들어, "o{1,3}" 은 "fooooood" 의 처음 세 개의 o 를 찾는다. "o{0,1}" 은 "o?" 와 같다. 쉼표와 숫자 사이에는 공백을 넣을 수 없다. |
| ? | 이 문자가 다른 한정 부호(*, +, ?, {n}, {n,}, {n,m})의 바로 뒤에 나올 경우 일치 패턴은 제한적이다. 기본값인 무제한 패턴은 가능한 많은 문자열을 찾는 데 반해 제한적인 패턴은 가능한 적은 문자열을 찾는다. 예를 들어, "oooo" 문자열에서 "o+?" 는 "o" 한 개만 찾고, "o+" 는 모든 "o" 를 찾는다. |
| . | "\n" 을 제외한 모든 단일 문자를 찾는다. "\n" 을 포함한 모든 문자를 찾으려면 '[.\n]' 패턴을 사용한다. |
| (pattern) | pattern 을 찾아 검색한 문자열을 캡처합니다. 캡처한 문자열은 VBScript 의 경우 SubMatches 컬렉션, JScript의 경우 $0...$9 속성을 이용하여 결과로 나오는 Matches 컬렉션에서 추출할 수 있다. 괄호 문자인 ( ) 를 찾으려면 "\(" 또는 "\)" 를 사용한다. |
| (?:pattern) | pattern 을 찾지만 검색한 문자열을 캡처하지 않는다. 즉, 검색한 문자열을 나중에 사용할 수 있도록 저장하지 않는 비캡처 검색이다. 이것은 패턴의 일부를 "or" 문자(|)로 묶을 때 유용하다. 예를 들어, 'industr(?:y|ies) 는 'industry|industries' 보다 더 경제적인 식이다. |
| (?=pattern) | 포함 예상 검색은 pattern 과 일치하는 문자열이 시작하는 위치에서 검색할 문자열을 찾는다. 이것은 검색한 문자열을 나중에 사용할 수 있도록 캡처하지 않는 비캡처 검색이다. 예를 들어, "Windows(?=95|98|NT|2000)" 는 "Windows 2000" 의 "Windows" 는 찾지만 "Windows 3.1" 의 "Windows" 는 찾지 않는다. 예상 검색은 검색할 문자열을 찾은 후 예상 검색 문자열을 구성하는 문자 다음부터가 아니라 마지막으로 검색한 문자열 바로 다음부터 찾기 시작한다. |
| (?!pattern) | 제외 예상 검색은 pattern 과 일치하지 않는 문자열이 시작하는 위치에서 검색할 문자열을 찾는다. 이것은 검색한 문자열을 나중에 사용할 수 있도록 캡처하지 않는 비캡처 검색이다. 예를 들어, "Windows(?!95|98|NT|2000)" 는 "Windows 3.1" 의 "Windows" 는 찾지만 "Windows 2000" 의 "Windows" 는 찾지 않는다. 예상 검색은 검색할 문자열을 찾은 후 예상 검색 문자열을 구성하는 문자 다음부터가 아니라 마지막으로 검색한 문자열 바로 다음부터 찾기 시작한다. |
| x|y | x 또는 y 를 찾는다. 예를 들어, "z|food" 는 "z" 또는 "food" 를 찾는다. "(z|f)ood" 는 "zood" 또는 "food" 를 찾는다. |
| [xyz] | 문자 집합이다. 괄호 안의 문자 중 하나를 찾는다. 예를 들어, "[abc]" 는 "plain" 의 "a" 를 찾는다. |
| [^xyz] | 제외 문자 집합이다. 괄호 밖의 문자 중 하나를 찾는다. 예를 들어, "[^abc]" 는 "plain" 의 "p" 를 찾는다. |
| [a-z] | 문자 범위이다. 지정한 범위 안의 문자를 찾는다. 예를 들어, "[a-z]" 는 "a" 부터 "z" 사이의 모든 소문자를 찾는다. |
| [^a-z] | 제외 문자 범위이다. 지정된 범위 밖의 문자를 찾는다. 예를 들어, "[^a-z]" 는 "a" 부터 "z" 사이에 없는 모든 문자를 찾는다. |
| \b | 단어의 경계, 즉 단어와 공백 사이의 위치를 찾는다. 예를 들어, "er\b" 는 "never" 의 "er" 는 찾지만 "verb" 의 "er" 는 찾지 않는다. |
| \B | 단어의 비경계를 찾는다. "er\B" 는 "verb" 의 "er" 는 찾지만 "never" 의 "er" 는 찾지 않는다. |
| \cx | X 가 나타내는 제어 문자를 찾는다. 예를 들어, \cM 은 Control-M 즉, 캐리지 리턴 문자를 찾는다. x 값은 A-Z 또는 a-z 의 범위 안에 있어야 한다. 그렇지 않으면 c 는 리터럴 "c" 문자로 간주된다. |
| \d | 숫자 문자를 찾는다. [0-9] 와 같다. |
| \D | 비숫자 문자를 찾는다. [^0-9] 와 같다. |
| \f | 폼피드 문자를 찾는다. \x0c 와 \cL 과 같다. |
| \n | 줄 바꿈 문자를 찾는다. \x0a 와 \cJ 와 같다. |
| \r | 캐리지 리턴 문자를 찾는다. \x0d 와 \cM 과 같다. |
| \s | 공백, 탭, 폼피드 등의 공백을 찾는다. "[ \f\n\r\t\v]" 와 같다. |
| \S | 공백이 아닌 문자를 찾는다. [^ \f\n\r\t\v] 와 같다. |
| \t | 탭 문자를 찾는다. \x09 와 \cI 와 같다. |
| \v | 수직 탭 문자를 찾는다. \x0b 와 \cK 와 같다. |
| \w | 밑줄을 포함한 모든 단어 문자를 찾는다. '[A-Za-z0-9_]' 와 같다. |
| \W | 모든 비단어 문자를 찾는다. "[^A-Za-z0-9_]" 와 같다. |
| \xn | n 을 찾는다. 여기서 n 은 16 진수 이스케이프 값이다. 16 진수 이스케이프 값은 정확히 두 자리여야 한다. 예를 들어, '\x41' 은 "A" 를 찾고 '\x041' 은 '\x04' 와 "1" 과 같다. 정규식에서 ASCII 코드를 사용할 수 있다. |
| \num | num 을 찾는다. 여기서 num 은 양의 정수이다. 캡처한 문자열에 대한 역참조이다. 예를 들어, '(.)\1' 은 연속적으로 나오는 동일한 문자 두 개를 찾는다. |
| \n | 8 진수 이스케이프 값이나 역참조를 나타낸다. \n 앞에 최소한 n 개의 캡처된 부분식이 나왔다면 n 은 역참조이다. 그렇지 않은 경우 n 이 0 에서 7 사이의 8 진수이면 n 은 8 진수 이스케이프 값이다. |
| \nm | 8 진수 이스케이프 값이나 역참조를 나타낸다. \nm 앞에 최소한 nm 개의 캡처된 부분식이 나왔다면 nm 은 역참조이다. \nm 앞에 최소한 n 개의 캡처가 나왔다면 n 은 역참조이고 뒤에는 리터럴 m 이 온다. 이 두 경우가 아닐 때 n 과 m 이 0 에서 7 사이의 8 진수이면 \nm 은 8 진수 이스케이프 값 nm 을 찾는다. |
| \nml | n 이 0 에서 3 사이의 8 진수이고 m 과 l 이 0 에서 7 사이의 8 진수면 8 진수 이스케이프 값 nml 을 찾는다. |
| \un | n 은 4 자리의 16 진수로 표현된 유니코드 문자이다. 예를 들어, \u00A9 는 저작권 기호(©)를 찾는다. |
대번에 보기에도 메타 문자의 수가 상당히 많고 그 내용도 복잡해 보인다. 이해를 돕기 위해서 실제로 메타 문자를 사용하여 정규 표현식 패턴을 한 가지를 만들어 보도록 하겠다.
비교적 간단한 경우인 핸드폰 번호를 정규 표현식 패턴으로 만들어 보도록 한다. 핸드폰 번호는 일반적으로 이통사의 고유 번호 3자리, 국번 3자리, 끝 번호 4자리로 이루어진다. 여기에서 각 번호간의 구분은 '-'로 한다고 임의로 정하도록 하겠다. 즉, '123-456-7890'과 같은 형태가 된다고 가정하는 것이다.
위의 표를 살펴보면 메타 문자 \d가 숫자 문자 한 문자를 나타낸다는 것을 알 수 있다. 따라서, 다음과 같은 정규 표현식 패턴을 만들 수 있다.
\d{3}-\d{3}-\d{4}
여기까지는 매우 쉽게 이해될 것이다. 즉, 이 정규 표현식 패턴이 의미하는 바는 숫자 3글자 다음에 '-' 기호가 나오고, 그 다음에 또 다시 숫자 3글자가 나오고, 그 다음에 또 '-' 기호가 나오고 마지막으로 숫자 4글자가 나온다는 의미인 것이다. 그런데, 요즘은 핸드폰이 워낙 많이 보급되다 보니 국번의 경우 3자리 번호만 가지고서는 숫자가 많이 부족하게 되었다. 그래서, 이젠 국번이 4자리인 핸드폰 번호도 주변에서 심심치 않게 접할 수 있는 것으로 알고 있다. 그렇다면 그런 4자리 국번을 가진 핸드폰 번호를 수용할 수 있도록 만들기 위해서는 위의 정규 표현식 패턴을 어떻게 바꾸는 것이 좋을까? 아마 다음과 같은 방법도 있을 수 있을 것이다.
\d{3}-(\d{3}|\d{4})-\d{4}
폰트 때문에 보기가 좀 힘들겠지만 파이프 문자(|)는 마치 OR 연산자와 같은 역활을 한다. 따라서, 위와 같이 파이프 문자와 소괄호를 함께 사용하면 지금과 같은 문제를 쉽게 해결할 수 있다. 그런데, 이렇게 변형된 정규 표현식 패턴은 비록 틀렸다고 말할 수는 없겠지만 아직 해결해야 할 문제점들을 몇 가지 가지고 있다.
그 중 한 가지 문제점은 소괄호 때문에 발생하는데, 이는 정규 표현식 패턴상에서 소괄호가 매우 특이한 기능을 한 가지 갖고 있기 때문이다. 이에 대한 더욱 자세한 내용은 Replace() 메서드에 관하여 설명하면서 다시 언급하겠지만 바로 역참조라는 기능 때문인데, 대상 문자열이 정규 표현식 패턴과 일치할 경우 소괄호 안에 감싸인 문자열 부분은 메모리에 미리 지정된 이름의 변수로 저장된다. 따라서, 지금과 같이 저장된 내부 변수를 재사용하지 않는 단순한 예에서는 쓸모 없이 메모리만 낭비하는 셈이다. 결국, 이 정규 표현식 패턴은 다시 다음과 같이 수정된다.
\d{3}-(?:\d{3}|\d{4})-\d{4}
이렇게 수정하고 나면 비로서 메모리에 아무런 변수도 생기지 않는 효율적인 정규 표현식 패턴이 만들어진다. 그러나, 아직도 또 다른 문제점이 하나 남아있는데 현재 상태와 같은 정규 표현식 패턴은 대상 문자열 내부에 패턴과 일치하는 문자열이 존재하기만 하면 무조건 그 조건이 만족된다. 따라서, 만약 실무에서 원하는 작업이 사용자들로부터 정확한 핸드폰 번호를 입력받기를 원하는 것이라면 완벽한 해결책은 되지 못하는 셈이 된다.
구체적으로 말해서 우리가 원하는 '123-456-7890'이나 '123-4567-8901'과 같은 형태의 핸드폰 번호 뿐만이 아니라 전혀 쓸모 없는 문자가 포함된 ' 123-456-7890'라든가 '123-456-7890 ABC'와 같은 형태의 문자열까지도 조건을 만족하게 되는 것이다. 따라서 순수한 핸드폰 번호 그 자체만을 만족시키려면 또 다시 다음과 같이 수정되야 한다.
^\d{3}-(?:\d{3}|\d{4})-\d{4}$
위의 표에서 찾아보면 알 수 있듯이 ^은 문자열의 맨 처음을, $는 문자열의 맨 마지막을 의미한다. 따라서, 이렇게 수정된 정규 표현식 패턴은 핸드폰 번호 그 자체 외에는 어떠한 문자열도 조건을 만족시키지 않게 되고, 비로서 어느 정도 만족할만 하게 작성되었다고 말할 수 있을 것이다.
그러나, 한 가지 유의해야 할 점은 정규 표현식의 패턴에는 정답이 없다는 것이다. 단적인 예로, 이 정규 표현식 패턴은 실무적인 요구 조건에 대해서 좀 더 명확한 유효성을 보장받기 위해서 또 다시 다음과 같이 수정될 수도 있다.
^0(?:11|16|17|18|19)-(?:\d{3}|\d{4})-\d{4}$
이 정규 표현식 패턴은 현실 세계에 실제로 존재하는 이통사의 번호만을 만족한다. 이처럼 정규 표현식 패턴은 좀 더 효율적인 패턴과 좀 더 비효율적인 패턴으로 구분될 수 있을 지는 모르겠지만, 사지선다형 문제에서와 같은 확실한 정답은 없다는 것이 필자의 개인적인 의견이다.
글을 쓰다보니 처음의 예상과는 달리 얘기가 길어지게 되었다. 다음글에서는 실제로 정규 표현식을 사용하여 작성한 샘플 코드를 살펴보도록 하겠다.
- ASP(Active Server Page)는 프로그래밍 언어가 아니다. 2002-03-15 00:00
- Microsoft Windows Script 5.6과 VBScript 5.6 2002-03-15 00:00
- VBScript 5.6과 정규 표현식(Regular Expression) 2002-04-14 20:15
- RegExp.Test() 메서드와 RegExp.Execute() 메서드의 활용 2002-04-29 11:24
- RegExp.Replace() 메서드의 활용 2002-05-26 22:49
- VBScript 5.6과 클래스(Class) 2002-06-19 12:31
- 접근 제한문, Initialize 이벤트와 Terminate 이벤트, 그리고 프로퍼티 프로시저 2002-08-19 16:08
- 인자를 가진 프로퍼티와 디폴트 프로퍼티(Default Property) 2002-09-11 09:12
- 그 밖의 유용한 VBScript 5.X 버전의 기능들 2002-11-03 16:19
- 기존의 ASP 프로그램을 이용한 간단한 스케줄링 잡(Scheduling Job) 설정 2003-02-21 10:31
- FileCube 버전 0.0.3 (설치 방법 및 기타 관련 정보) 2003-05-26 09:31
- FileCube 버전 0.0.4 (커스텀 레코드셋으로 구현한 정렬 기능) 2003-09-15 12:28
- 인터넷 익스플로러 스크립팅 개체와 인터페이스 2004-01-07 09:06
- 인터넷 익스플로러가 HTML을 처리하는 기본적인 방법에 대한 이해 2004-03-29 14:54
- 재미있는 자바스크립트 01, TABLE 태그와 HTCs의 활용 2005-04-25 14:00
- 재미있는 자바스크립트 02, HTCs의 작성 2005-07-13 09:18
- 재미있는 자바스크립트 03, HTCs의 작성과 ASP.NET 사용자 지정 컨트롤 연동 2006-05-25 16:49




